NoSQL
Dans ce laboratoire, nous allons voir une base de données orientée graphe. Mais avant d'en discuter, nous devons refaire une petite mise en contexte. Nous allons revenir à une époque où l'euro n'existait pas: les années 90 ! Lors d'une interview, Kevin Bacon (l'acteur de Footlose) expliquait qu'il avait travaillé avec tout le monde à Hollywood. Trois étudiants d'Albright ont pris un peu trop sérieusement cette affirmation. Lors d'un talk-show, ils ont exposé leur théorie des "six degrées de Kevin Bacon" prouvant ainsi que Kevin Bacon est bien le centre du "cinématique-univers"
Derrière ce fait divers se cache une vraie théorie: celui des six degrés de séparation. Le degré de séparation mesure le nombre de personnes entre vous et une autre personne:
- 0: De vous à vous
- 1: Entre vous et une personne que vous connaissez
- 2: Entre une personne que vous ne connaissez pas, mais que vos proches connaissent
- 3: ...
Cette théorie dit qu'il a, en général, au maximum 6 degrés entre vous et n'importe qui sur Terre. Nous pourrions en parler plus en profondeur, mais la théorie des graphes (qui regroupent l'ensemble des théories se portant sur les graphes) est un autre sujet de discussion que l'on ne va pas approfondir ici.
Mais si on en parle ici, c'est parce que les graphes ont été de plus en plus utilisés dans les applications modernes. Quelle application connue n'a pas un système de recommandations (achats, amis, films, livres, etc) ?
On peut s'amuser à utiliser une base de données SQL, ce n'est qu'une question de quelques jointures. Mais autant se simplifier la tâche en utilisant une base de données appropriée à la situation. Ce laboratoire s'attardera donc sur Neo4J qui est une base de données NoSQL très connue. Si vous le désirez, vous pouvez voir cette petite vidéo de présentation (en anglais) pour avoir un aperçu de ce qu'il possible de faire.
Une petite vidéo de présentation (en anglais)
Prérequis
Dans ce laboratoire, nous allons utiliser plusieurs bases de données:
- Movies: une base de données disponible de base sur Neo4J pour s'entrainer
- MovieLens: Un gros dataset proposé par le groupe GroupLens
Pour vous faciliter le travail, nous allons construire une image custom qui contiendra le nécessaire pour ce laboratoire.
Téléchargez ce Dockerfile et ouvrez un terminal dans le dossier. Exécutez la commande suivante:
docker build -t neo .
Le build prendra un peu de temps, car Docker va charger le fichier de sauvegarde mis à disposition par MovieLens.
Ensuite, exécutez la commande suivante:
docker run -p 7474:7474 -p 7687:7687 -m 2G neo
Premiers pas avec Neo4J

Nous allons utiliser le guide de base proposé pour apprendre Neo4J. Dans votre navigateur, rendez-vous à l'adresse suivante: http://localhost:7474
Dans la partie login, choississez "No authentification" comme ceci:
Ensuite, envoyez l'instruction suivante qui permet de lancer le guide (il faut cliquer sur la flèche bleue):
:guide movies

Dans la fenêtre latérale qui vient de s'ouvrir, cliquez sur la page 2. Ensuite, sur le code pour qu'il soit mis au bon endroit. Il vous suffit de cliquer sur la flèche bleue pour avoir la DB de démo.
Pour le reste de ce laboratoire, je ne vais m'attarder que sur les éléments clés du guide qui seront intéressants pour ce laboratoire. Vous pouvez très bien le faire complètement si vous désirez en connaître plus sur le sujet :)
Nous allons voir la structure de base de cette DB ainsi que les opérations de base.
Structures de base
En Neo4J, nous avons deux structures:
- Les nœuds (représentés par des
()dans les requêtes) - Les relations (représentées par des
[]dans les requêtes)
Les nœuds correspondent aux entités (ils sont "typés"). Dans les données insérées précédemment, nous avions par exemple:
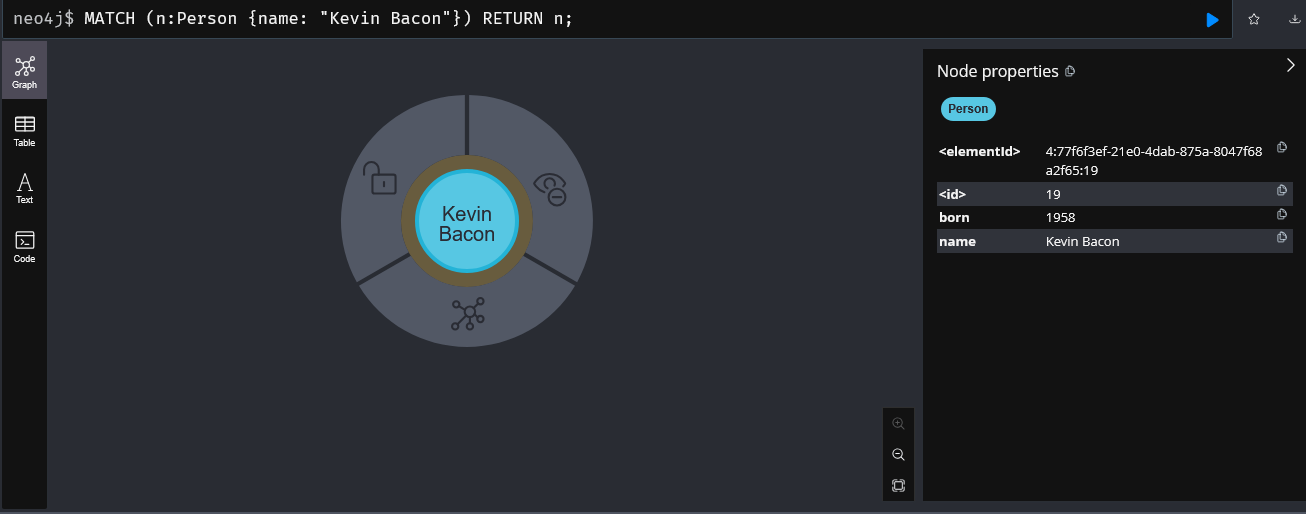
Vous noterez que notre noeud possède des propriétés qui sont les données qui le caractérisent. Comme souvent, en NoSQL, chaque noeud peut avoir des propriétés différentes (même s'ils sont du même type).
Les relations sont les liens entre les nœuds. Le point fort de Neo4J est de pouvoir donner des propriétés aux relations ! Dans nos données, nous pouvons par exemple voir les rôles de Kevin Bacon dans ses films:
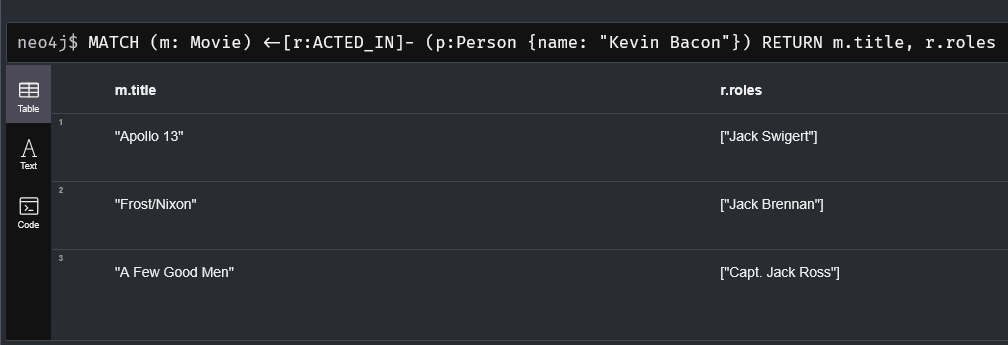
Sur l'image, vous pouvez voir que j'ai affiché la propriété "rôle" de la relation de type ACTED_IN.
Dans les requêtes, il est possible de définir les types des entitées ainsi que des variables pour pouvoir être utilisées plus tard:
MATCH (variableNoeud:TypeDeNoeud) -[variableRelation:TypeRelation]-> (:AutreTypeDeNoeud)
Ce sont les : qui permettent de séparer la variable du type d'entité.
Rechercher
Dans ce laboratoire, on va surtout s'intéresser à la recherche de données. On ne va donc pas voir ce qui est lié à la création, modification ou suppression de données.
Nous avons l'instruction MATCH qui permet de demander un nœud ou une relation qui correspondra à notre critère de recherche et RETURN qui permet de renvoyer des entités (relation ou nœuds) ainsi que certaines propriétés de ces entités.
La première possibilité consiste à avoir une correspondance parfaite avec notre critère:
MATCH (p:Person {name: "Kevin Bacon") RETURN p;
Cette requête permet de trouver l'ensemble des nœuds (ici, un seul) qui a une propriété name qui vaut exactement la valeur décrite: Kevin Bacon.
Vous comprenez que c'est fort limité pour certaines recherches.
Par exemple, si nous souhaitons trouver tous les acteurs qui s'appellent "Kevin", nous sommes dans l'impossibilité d'utiliser cette approche.
Nous avons besoin d'un deuxième mot clé: WHERE.
Nous pouvons ainsi utiliser des conditions plus avancées.
MATCH (p:Person) WHERE p.name =~ "Kevin .*" RETURN p
Vous l'aurez remarqué, pas de LIKE comme en SQL, mais des regex ! 1
Votre réaction quand vous avez vu la regex

Produit cartésien
À l'instar de SQL, il est possible que Neo4J produise un produit cartésien à cause de votre requête.
Pour rappel, quand SQL n'arrive pas à trouver une correspondance unique avec une autre ligne lors d'un join, un produit cartésien est généré.
Par exemple: si vous faites une jointure de la table1 et la table2 et qu'une ligne de table1 peut être "joined" avec 2 lignes de table2, le résultat final produit 2 lignes (1 ligne (de la table table1) * 2 lignes (de la table table2)).
En revanche, si nous avions eu 2 lignes de la table1, nous aurions eu 4 lignes dans le résultat final (2 lignes (de la table table1) * 2 lignes (de la table table2)).
Ce même phénomène peut se produire dans Neo4J à partir du moment où deux MATCH renvoient des noeuds sans aucune relation entre eux.
Par exemple:
MATCH (p:Person)-[:ACTED_IN]->(:Movie)
MATCH (p2:Person)-[:DIRECTED]->(:Movie)
RETURN p.name AS acteur, p2.name AS réalisateur
Cette requête va générer un produit cartésien, car rien ne relie les nœuds du premier MATCH avec le second.
Donc, chaque nœud du premier MATCH sera combiné à chaque nœud du second MATCH.
En revanche, cette requête ne produira aucun produit cartésien:
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
MATCH (p2:Person)-[:DIRECTED]->(m)
RETURN p.name AS acteur, p2.name AS réalisateur, m.title AS film
En effet, le second MATCH utilise les films (m) du premier pour trouver p2. Dès lors, il n'y a plus besoin de faire un produit cartésien.
Pour ce laboratoire, il n'y a pas de souci de performance, car le dataset est relativement petit. Mais dans des datasets plus imposants, vous risquez d'avoir de mauvaises surprises.
WHERE
Le WHERE va nous permettre de filtrer les nœuds ou relations en fonction de certains critères.
Si vous avez tout suivi jusqu'ici, vous pourriez me dire que le MATCH le faisait déjà.
Pour tout ce qui est égalité, c'est vrai.
Mais pour tout le reste, vous êtes obligés d'utiliser le WHERE.
Si vous voulez tous les acteurs avec une année de naissance supérieure à 1987, vous devrez utiliser le WHERE dans cette requête:
MATCH (p:Person)
WHERE p.born > 1987
RETURN p.name
Dernier détail, il n'y a pas de != pour la différence.
À la place, vous devrez utiliser <>.
Pour rendre les choses plus compliquées, vous pouvez utiliser WHERE avec des patterns pour filtrer encore plus efficacement.
WITH 2000 AS minYear
MATCH (a:Person)-[r:KNOWS WHERE r.since < minYear]->(b:Person)
RETURN a.name AS person, b.name AS friend, r.since AS knowsSince
(source: https://neo4j.com/docs/cypher-manual/5/clauses/where/#fixed-length-patterns)
Ici, nous filtrons pour ne garder que les relations où r.since est inférieur à minYear (ici 2000).
WITH
WITH permet de chaîner les requêtes, ce qui est extrêmement pratique quand une requête se fait par étape.
Prenons un exemple:
- Je souhaite d'abord compter le nombre de films con�çus pour chaque réalisateur
- Ensuite, je voudrais filtrer ceux qui ont au moins fait 2 films
- Enfin, je voudrais conserver uniquement ceux qui ont travaillé avec Kevin Bacon.
Pour la première partie, c'est facile:
MATCH (p:Person) -[:DIRECTED]->(:Movie)
RETURN p as Réalisateur, COUNT(*) as NbMovies
Le problème de cette approche, c'est qu'il est impossible d'enchaîner les autres requêtes.
Avec le WITH, tout ce que nous créons sera accessible à la partie suivante.
Donc, en remplaçant le RETURN avec un WITH, nous pouvons réaliser le deuxième point:
MATCH (p:Person) -[:DIRECTED]->(:Movie)
WITH p as Réalisateur, COUNT(*) as NbMovies
WHERE NbMovies > 1
Enfin, le WITH reste valable et nous pouvons donc utiliser un MATCH pour la troisième partie en réutilisant les variables que nous avions définies avec le WITH:
MATCH (p:Person) -[:DIRECTED]->(:Movie)
WITH p as Réalisateur, COUNT(*) as NbMovies
WHERE NbMovies > 1
MATCH (Réalisateur) -[:DIRECTED]-> (m:Movie) <-[:ACTED_IN]-(bacon:Person {name: "Kevin Bacon"})
RETURN DISTINCT Réalisateur.name, NbMovies
Calcul de la plus courte distance
Il est tout à fait possible de "s'amuser" avec les calculs de distance dans Neo4J.
Par exemple, nous pourrions demander quels sont les acteurs "proches" de Kevin Bacon. Par proche, nous allons supposer à un degré de séparation égal ou inférieur à 4 (0 exclu).
MATCH (bacon:Person {name:"Kevin Bacon"})-[*1..4]-(p:Person)
RETURN DISTINCT p
Ici, nous demandons à la DB de nous fournir les nœuds (sans doublon) de type Person avec une distance minimale de 1 et au maximum de 4. Cette syntaxe élégante permet de filtrer nos cibles (l'ensemble de la syntaxe est décrite ici, je vous conseille vivement de prendre connaissance des règles possibles).
Si nous souhaitons trier par ordre de distance, comment pourrait-on réaliser la requête ?
Dans Neo4J, il existe la fonction shortestPath qui prend comme argument un pattern.
Ce pattern décrit un ensemble composé de nœuds et de relations.
Prenons un exemple:
MATCH (bacon:Person {name: "Kevin Bacon"}) //1. On prend notre noeud de départ
MATCH (p:Person) //2. On filtre tous les noeuds pour ne prendre que ceux qui sont des personnes
WHERE p <> bacon //3. On évite d'avoir un noeud 'p' identique à 'bacon' pour le calcul du plus court chemin
MATCH path = shortestPath((bacon)-[*..4]-(p)) //4. Ici, nous prenons que les chemins les plus courts entre 'bacon' et 'p'.
// Ce chemin DOIT correspondre au pattern décrit (maximum 4 relations).
// Sans limite, Neo4J risque de faire trop de caculs (ici, ce n'est pas grave car le graphe est petit. Mais cela ne fonctionnera plus pour les exercices avec un graphe plus important)
RETURN p.name, length(path) AS Hops, path // 5. On renvoie le nom de la personne, la longueur du chemin et le chemin complet
ORDER BY Hops, p.name // 6. On trie les résultats
- Nous utilisons la fonction
lengthpour directement calculer le nombre de sauts (degrés) - Nous ajoutons le path complet simplement pour vérifier la réponse. Il n'y a aucun autre intérêt mis à part pour s'assurer que le calcul est bon.
Système de recommandations
Et si nous souhaitons conseiller des acteurs à d'autres acteurs ? Voici les règles:
- Kevin Bacon doit avoir joué avec la personne qu'il conseille
- Kevin Bacon doit avoir joué avec la personne qu'il va recommander
- La personne conseillée et la personne recommandée ne doivent pas avoir joué ensemble
C'est parti !

Regardons avec qui Kevin Bacon a joué directement:
MATCH(bacon:Person {name: "Kevin Bacon"}) -[:ACTED_IN]-> (:Movie) <-[:ACTED_IN]- (p:Person)
RETURN p.name
Nous voyons "Tom Hanks" ! Ce sera donc lui que l'on va conseiller.
MATCH (bacon:Person {name: "Kevin Bacon"}) -[:ACTED_IN]-> (:Movie) <-[:ACTED_IN]- (personneConseillee:Person)
WHERE NOT (personneConseillee) -[:ACTED_IN]-> (:Movie) <-[:ACTED_IN]- (:Person {name: "Tom Hanks"}) AND personneConseillee.name <> "Tom Hanks"
RETURN DISTINCT personneConseillee.name
Si on regarde de plus près la requête, il s'agit d'une application littérale des règles données plus haut:
//1. On cherche toutes les personnes qui ont joué avec Kevin Bacon
MATCH (bacon:Person {name: "Kevin Bacon"}) -[:ACTED_IN]-> (:Movie) <-[:ACTED_IN]- (personneConseillee:Person)
//2. On filtre ces personnes pour ne prendre que ceux qui n'ont pas joué avec Tom Hanks
WHERE NOT (personneConseillee) -[:ACTED_IN]-> (:Movie) <-[:ACTED_IN]- (:Person {name: "Tom Hanks"})
//3. On retire Tom Hanks également
AND personneConseillee.name <> "Tom Hanks"
//4. On renvoie les différents noms sans doublon
RETURN DISTINCT personneConseillee.name
C'est ce qui fait la force de Neo4J. On est beaucoup plus proche de la façon de penser d'un humain que de penser en termes de jointures.
D'ailleurs, on peut très facilement généraliser le problème. On a généré une liste pour Tom Hanks, mais il n'est pas le seul à vouloir des conseils ! Si on souhaite conseiller tout le monde:
MATCH (bacon:Person {name: "Kevin Bacon"})-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(p1:Person)
WHERE p1 <> bacon
MATCH (bacon:Person {name: "Kevin Bacon"})-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(p2:Person)
WHERE p2 <> bacon
AND p1 <> p2
AND NOT (p1)-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(p2)
RETURN p1.name, collect(DISTINCT p2.name) AS recommandations
Décomposons la requête ensemble:
- On prend toutes les personnes qui ont joué avec Kevin Bacon
MATCH (bacon:Person {name: "Kevin Bacon"})-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(p1:Person)
WHERE p1 <> bacon
On doit bien vérifier que p1 est différent de bacon.
En effet, si Kevin Bacon avait eu un double rôle dans un même film, il correspondrait à la recherche.
Est-ce possible d'avoir un double rôle ?
Oui, par exemple dans le film "Les visiteurs", Christian Clavier joue deux rôles.
- On reprend les personnes qui ont travaillé avec Kevin Bacon et, en plus du même filtre qu'au point 1, on vérifie que
p1est différent dep2. Enfin, on doit s'assurer quep1etp2n'ont pas joué ensemble (sinon, ils se connaissent déjà). Comme vous vous en doutez, le doubleMATCHva provoquer un produit cartésien.
MATCH (bacon:Person {name: "Kevin Bacon"})-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(p2:Person)
WHERE p2 <> bacon
AND p1 <> p2
AND NOT (p1)-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(p2)
- Il ne reste plus qu'à renvoyer le nom de l'acteur que l'on conseille (
p1) avec une liste de noms d'acteurs (p2). La fonctioncollectpermet de grouper des valeurs en liste
RETURN p1.name, collect(DISTINCT p2.name) AS recommandations
Exercices

Prérequis
Pour fonctionner, nous allons devoir initialiser notre dataset. Lors de la création de l'image Docker, les fichiers CSV avec les informations ont été chargés. Nous pouvons indiquer à Neo4J de charger ces fichiers pour pouvoir manipuler les données.
D'abord, supprimons nos données du guide via cette commande:
MATCH (n)
DETACH DELETE n
Ensuite, nous pouvons charger les données du nouveau dataset:
CREATE CONSTRAINT IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS FOR (u:User) REQUIRE u.userId IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS FOR (g:Genre) REQUIRE g.name IS UNIQUE;
LOAD CSV WITH HEADERS FROM 'file:///movies.csv' AS row
MERGE (m:Movie {movieId: toInteger(row.movieId)})
SET m.title = row.title
WITH m, split(row.genres, '|') AS genreList
UNWIND genreList AS genreName
MERGE (g:Genre {name: genreName})
MERGE (m)-[:HAS_GENRE]->(g);
LOAD CSV WITH HEADERS FROM 'file:///ratings.csv' AS row
MERGE (u:User {userId: toInteger(row.userId)})
MERGE (m:Movie {movieId: toInteger(row.movieId)})
MERGE (u)-[r:RATED]->(m)
SET r.rating = toFloat(row.rating),
r.timestamp = toInteger(row.timestamp);
LOAD CSV WITH HEADERS FROM 'file:///tags.csv' AS row
MERGE (u:User {userId: toInteger(row.userId)})
MERGE (m:Movie {movieId: toInteger(row.movieId)})
MERGE (u)-[t:TAGGED]->(m)
SET t.tag = row.tag,
t.timestamp = toInteger(row.timestamp);
Tout est chargé, nous pouvons y aller !
Exercices faciles
- Listez tous les films avec leur movieId et title
- Trouvez les
userIddes utilisateurs ayant noté le film "Toy Story (1995)" - Calculez la moyenne des notes données à "Jumanji (1995)"
- Voir tous les tags donnés au film "Toy Story (1995)", comptez le nombre de fois où chaque tag apparaît et les classez par ordre décroissant de fréquences
- Listez les 5 films les mieux notés avec un minimum de 10 avis
Exercices difficiles
- Listez tous les films du genre "Comedy"
- Trouvez les utilisateurs qui ont noté les mêmes films que l'utilisateur avec l'ID 100
- Recommandez des films à l'utilisateur 100 qu'il n'a pas vus, notés par des utilisateurs proches (qui ont noté au moins un même film que lui)
- Trouvez les tags les plus utilisés par l'utilisateur avec l'ID 474
- Trouvez les films qui partagent au moins 2 tags avec "Toy Story (1995)"
Exercices orientés graphe
- Écrivez une requête qui retourne les 10 films les mieux notés (note >= 4) par l'utilisateur ayant l'ID 42, triés par note décroissante puis par titre.
- Identifiez les 5 utilisateurs qui ont le plus de films en commun notés avec l'utilisateur avec l'ID 42 (peu importe la note). Retournez ces utilisateurs avec le nombre de films en commun.
- Recommandez 5 films à l'utilisateur 42 qu'il n'a pas encore notés, mais qui ont été notés >= 4 par les utilisateurs similaires identifiés au point précédent.
- Pour l'utilisateur avec l'ID 42, déterminez quel est son genre préféré en fonction des notes moyennes qu'il donne aux films de chaque genre. Retournez les genres triés par moyenne décroissante.
- Trouvez les films, avec un ID plus petit que 2000, liés entre eux par les utilisateurs (c'est-à-dire qui ont été notés par deux utilisateurs différents). Comptez le nombre de fois où ils sont liés par des utilisateurs et filtrez le résultat pour que ce nombre soit au moins égal à 5. Enfin, triez par ce nombre et de façon décroissante.
Conclusion
Dans ce laboratoire, nous avons vu les bases de Neo4J avec les instructions de base. Nous n'avons pas été plus loin, car ce n'était pas l'objectif mais sachez que nous n'avons fait qu'effleurer la surface de Neo4J. Nous n'avons pas abordé la projection de graphes ainsi que les algorithmes de graphes. Par exemple, Google a utilisé son algorithme PageRank à ses débuts pour classer les sites dans les résultats de recherche. Au plus un site était important, au plus celui-ci devait être haut dans les résultats de recherche. L'algorithme permettait justement de générer un score pour chaque site référencé par Google. Dans notre cas, nous aurions pu essayer de trouver les films importants par genre: les fameux "movie to watch" que l'on peut retrouver sur certains sites. Une force de Neo4J est que ces algorithmes ont été codés et optimisés par l'équipe de développement. Il ne vous reste plus qu'à les utiliser.
Si le sujet vous intéresse, je vous invite à regarder la documentation sur le sujet. N'hésitez pas à expérimenter pour voir si vous pourriez créer le prochain Netflix !

Notes de bas de page
-
Pour ceux qui sont vraiment allergiques aux regex, il existe des méthodes pré-faites pour les cas de base. Mais qui n'aime pas les regex, sérieusement ? ↩