Laboratoire 2: Gestion de la consistence
Introduction
Ce laboratoire sera un peu particulier, car nous allons explorer comment les bases de données gèrent la consistance des données (en accès unique ou en accès parallèle). Vous devrez utiliser Docker ainsi que le fichier de restauration pour obtenir la base de données.
Prérequis
Vous devez avoir installé : Docker (voir document sur Moodle). Utilisez la commande suivante:
docker run -p 1433:1433 -m 2G --name sql1 -e ACCEPT_EULA=Y -e MSSQL_SA_PASSWORD=Password1 mcr.microsoft.com/mssql/server:2022-latest
La base de données sera disponible avec la configuration suivante :
- Adresse : localhost
- Port : 1433
- Utilisateur : sa
- Mot de passe : Password1
Vous devez ensuite créer une base de données appelée "exercices" via la commande SQL suivante dans DataGrip :
CREATE DATABASE exercices;
C'est cette base de données que nous utiliserons durant tout le laboratoire.
Mise en place
La base de données ne contiendra qu'une seule table : "compte" avec la structure suivante :
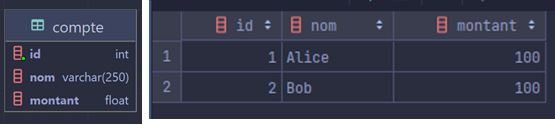
Pour la suite des exercices, il vous faudra 2 clients pour simuler des accès concurrents à la base de données. Vous n'aurez pas besoin de plusieurs logiciels. En effet, un même logiciel est capable d'exécuter plusieurs requêtes de manière concurrente ! Comme les navigateurs, ils possèdent un système d'onglets. Dans mon cas, j'ai renommé mes onglets "client1" et "client2" pour les retrouver plus facilement.
Je vous conseille également d'avoir à votre disposition un 3ème onglet avec la requête permettant de remettre la base de données dans son état original (et de la créer avant de commencer le laboratoire). Voici le contenu de la requête :
DROP TABLE IF EXISTS compte;
CREATE TABLE compte(
id int identity,
nom varchar(250),
montant float
);
INSERT INTO compte VALUES ('Alice', 100);
INSERT INTO compte VALUES ('Bob', 100);
SELECT * FROM compte;
Le SELECT à la fin permet de voir le contenu de la table pour s'assurer que tout est bon.
Création des clients avec DataGrip
Pour créer un nouveau client, vous devez créer un nouveau "terminal de requêtes" avec une nouvelle session (le but est de simuler plusieurs clients sur différentes connexions). Pour créer ce nouveau terminal, cliquez sur "+" et ensuite "Query Console":
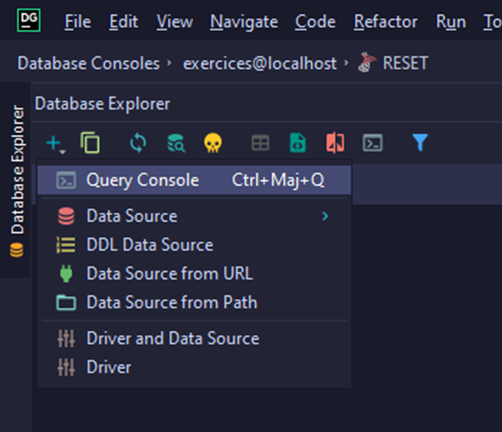
Un nouveau terminal est créé. Dans ce nouvel onglet, cliquez sur "console" (qui est la session par défaut), sélectionnez la base de données et choisissez "New Session".
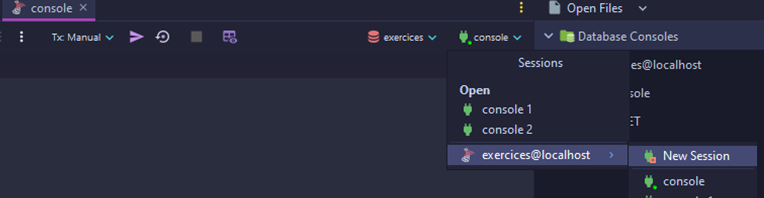
Il ne reste plus qu'une étape : renommez l'onglet pour un meilleur confort. Faites un clic droit sur l'onglet et renommez-le ("Rename File…") en "Client 1".
Répétez ces étapes pour le client 2.
Exercice 1: panne de courant
Pour ce premier exercice, il vous faudra avoir un terminal ouvert ou "Docker Desktop" à portée de main. Nous allons simuler une panne de courant (qui provoquera un redémarrage du système). Voici le contenu des requêtes des 2 clients (ne les exécutez pas encore) :
| N° étape | Client 1 | Client 2 |
| 1 | | |
L'instruction WAITFOR DELAY va permettre de mettre la requête en "pause" pendant un certain délai (ici, 3 minutes).
Cela nous permettra de représenter un "travail intensif" de la base de données et surtout de provoquer la panne au bon moment !
Vous ne disposerez que de 3 minutes pour faire cette opération, ne soyez donc pas distraits durant cette manipulation.
Pour provoquer un redémarrage du container, vous avez 2 options : via le terminal ou via le logiciel. Si vous optez pour la première solution, vous devrez utiliser la commande suivante :
Si vous êtes prêts, exécutez le code du client 1, puis du client 2 et faites un redémarrage de la base de données ! Dans le client de votre choix, faites la requête suivante :
SELECT * FROM compte;
Quelles valeurs voyez-vous ? Est-ce que cela vous semble correcte ? Quelle solution pourriez-vous mettre en place pour empêcher cela ? Si vous pensez avoir trouvé, appliquez votre idée en modifiant le code du client 1 et 2 pour que ce phénomène ne puisse plus se reproduire. N'oubliez pas d'effectuer une réinitialisation de la base de données avant votre prochain essai.
Exercice 2 : découverte des « dirty reads »
Maintenant que vous voyez l'utilité des transactions, nous allons pouvoir mettre en lumière tout un mécanisme d'isolation. Le niveau d'isolation d'une transaction peut être comparé à un niveau de "sécurité contre des anomalies". Ces anomalies sont provoquées par l'exécution en parallèle des requêtes. Nous allons visualiser le premier qui est le "dirty read".
Reprenez vos onglets "Client 1" et "Client 2", enlevez les requêtes précédentes et exécutez les étapes une à une (attention aux changements de client) :
| N° étape | Client 1 | Client 2 |
| 1 | | |
| 2 | |
Le client 2 voit des valeurs modifiées alors que le client 1 n'a pas terminé sa transaction:
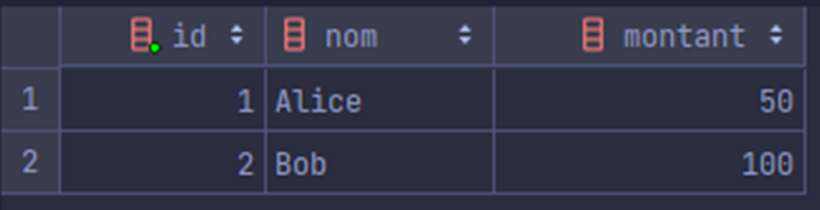
Ce phénomène est dû au niveau d'isolation du client 2.
Notez le SET TRANSACTION ISOLATION LEVEL qui est une instruction permettant de choisir le niveau d'isolation.
Dans cet exercice, vous voyez que notre client a un niveau d'isolation à READ UNCOMMITTED qui est le niveau le plus bas d'isolation.
Il permet de lire des modifications des transactions non terminées.
Pour éviter ce phénomène, nous allons utiliser le niveau d'isolation supérieur : READ COMMITED.
Comme son nom l'indique le READ COMMITED ne permet de lire que les modifications qui ont été validées suite à un COMMIT.
Tout d'abord, terminez les 2 transactions précédentes.
Effectuez un ROLLBACK dans les 2 cas pour ne pas devoir réinitialiser la base de données.
Si vous optez pour la solution du COMMIT, n'oubliez pas de procéder à la réinitialiser de la DB.
Avant de modifier nos clients, nous devons permettre les "snapshots" de notre base de données.
Exécutez la requête suivante dans n'importe quel client :
ALTER DATABASE exercices SET READ_COMMITTED_SNAPSHOT ON;
Maintenant, exécutez les requêtes suivantes :
| N° étape | Client 1 | Client 2 |
| 1 | | |
| 2 | |
Maintenant, vous devriez voir les "dirty reads" disparaître !
Veuillez noter que quand vous ne précisez aucun niveau d'isolation, le READ COMMITED est sélectionné par défaut.
Exercice 3 : découverte des « phantom reads »
Pour ce troisième exercice, réinitialisez la base de données et effacez le contenu de chaque client. Suivez les étapes suivantes :
| N° étape | Client 1 | Client 2 |
| 1 | | |
| 2 | | |
| 3 | |
Si vous comparez les 2 nombres que vous avez récupérés, vous verrez qu'ils sont différents.
Pourtant, le client 2 refait la même requête et devrait donc voir les mêmes nombres.
Nous voyons que le client 2 a le niveau de transaction par défaut, c'est-à-dire READ COMMITED.
Si nous reprenons la définition de ce niveau d'isolation, nous voyons que le client 2 pourra voir les modifications qui ont été validées.
Ce qui est le cas ici, ce qui pourrait provoquer des problèmes de consistance à cause des "lignes fantômes".
Nous avons à notre disposition un niveau d'isolation pour gérer cette anomalie : REPEATABLE READ.
Réinitialisez la base de données, effacez le code des clients et suivez les étapes :
| N° étape | Client 1 | Client 2 |
| 1 | | |
| 2 | | |
| 3 | |
Vous constatez dorénavant que les nombres sont bien égaux ! Mais les plus attentifs d'entre vous auront remarqué que le client 1 se "bloque" aussi longtemps que le client 2 n'a pas fini. Il s'agit d'une conséquence de notre niveau d'isolation. Ce dernier verrouille toutes les lignes parcourues dans la base de données pour assurer la répétition des lectures. À cause des verrous qui bloquent les lignes qui devraient être mises à jour par le client 1, ce dernier est bloqué. Quand le client 2 termine son exécution, les verrous sont supprimés et le client 1 peut reprendre.
Exercice 4 : dernier niveau
Est-ce que tout semble parfait ?

Réinitialisez la base de données, effacez le code des clients et suivez les étapes :
| N° étape | Client 1 | Client 2 |
| 1 | | |
| 2 | | |
| 3 | |
Vous voyez que les 2 nombres sont différents, mais pourquoi ?
En nous basant sur l'explication précédente, on comprend pourquoi.
La base de données possède 2 lignes qui sont parcourues par le client 2.
Celui-ci est en REPEATABLE READ et donc ces 2 lignes sont verrouillées.
Ensuite, une 3ème ligne est ajoutée à la table, mais elle n'a pas été verrouillée, car elle a été ajoutée après le SELECT du client 2.
Quand le client 2 fait son second SELECT, il parcourt les 2 lignes verrouillées et la troisième ligne.
Ce qui explique pourquoi nous obtenons cette différence.
La seule solution est le dernier niveau d'isolation : SERIALIZABLE.
Ce dernier garantit que la transaction aura "l'impression" qu'aucune autre transaction n'aura été exécutée en parallèle.
Pour le tester : réinitialisez la base de données, effacez le code des clients et suivez les étapes :
| N° étape | Client 1 | Client 2 |
| 1 | | |
| 2 | | |
| 3 | |
Vous voyez que les 2 nombres sont égaux !
Comme on pouvait s’y attendre le client 1 a été bloqué à cause des verrous qui ont été plus restrictifs.
Mais si vous retentez l’expérience en changeant la valeur insérée en "10", on pourrait se poser la question du blocage.
En effet, étant donné que la nouvelle ligne insérée ne sera pas comptée dans la fonction d’agrégat (10 étant plus petit que 100).
Cependant, vous verrez que le blocage existe toujours.
À nouveau, on peut imaginer facilement une situation qui poserait problème sans blocage : faites un INSERT suivi d’un UPDATE et vous aurez un changement au niveau du COUNT (insérez une valeur plus petite, ensuite faites une mise à jour pour que cette ligne soit comptabilisée par le COUNT).
Vous comprenez maintenant pourquoi même un INSERT qui semble innocent au premier abord doit être bloqué.
Vous vous en doutez, mais ce dernier niveau d’isolation est le plus gourmand en ressources (verrous plus restrictifs) et entraine donc plus de ralentissements.
Conclusion
Nous avons vu les différentes anomalies de lecture au niveau de la base de données et comment les contrer avec les niveaux d’isolation. Vous comprenez leur fonctionnement dans leur globalité et aussi pourquoi les niveaux d’isolation les plus forts entrainent des ralentissements (à tel point que les transactions sont parfois réellement exécutées une à une !). Il convient donc de toujours analyser la situation pour opter pour le bon niveau d’isolation (pas trop faible pour éviter les anomalies, mais pas trop fort pour ne pas ralentir le système inutilement).