Laboratoire 1: Index
Dans ce laboratoire, vous verrons comment gérer les requêtes lentes de la base de données :
- Comprendre pourquoi elles sont lentes
- Comment y remédier
Prérequis
Vous devez avoir installé : Docker (voir document sur Moodle).
- Installez l’image de Microsoft SQL Server : téléchargez le fichier ".tar.xz" présent sur Moodle et exécutez la commande suivante :
docker load -i CHEMIN_IMAGE
L'image correspond au fichier .tar.xz que vous avez téléchargée sur Moodle.
- Reprenez votre terminal et exécutez la commande suivante et attendez une petite minute (l’option
--rmpermet de supprimer automatiquement le container quand celui-ci s’éteindra) :
docker run -m 2G --cpus="0.3" --name sql1 -d -p 1433:1433 --rm mssql:index
La base de données sera disponible avec la configuration suivante :
- Adresse : localhost
- Port : 1433
- Utilisateur : sa
- Mot de passe : Password1
- Base de données : exercices
Vous pouvez utiliser n’importe quel outil de votre choix pour ce labo : votre IDE, DBeaver, etc. Dans la suite du laboratoire, vous n’aurez pas besoin d’un outil spécifique. Je vous présente comment faire avec le logiciel DataGrip (que vous pouvez utiliser gratuitement avec votre adresse email d’étudiant).
- Ajoutez une nouvelle source :
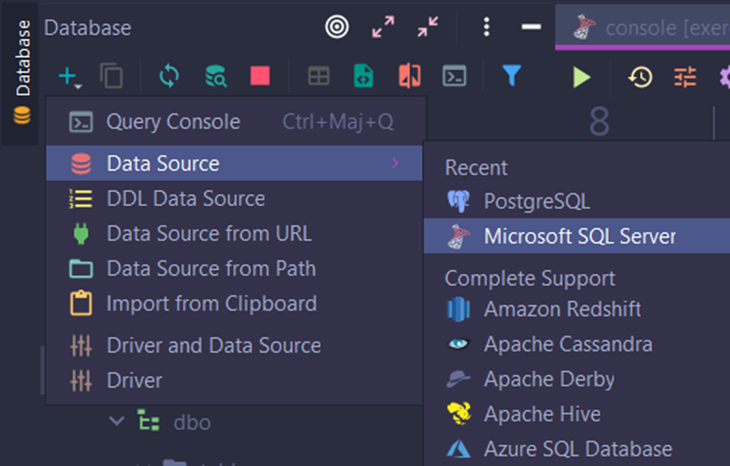
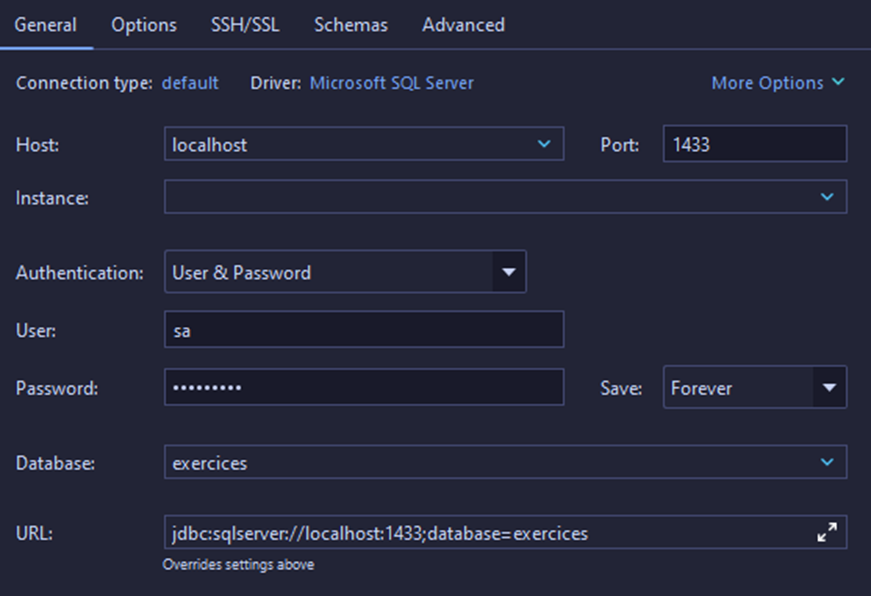
- Ajoutez les informations suivantes (rappel : le mot de passe est
Password1):
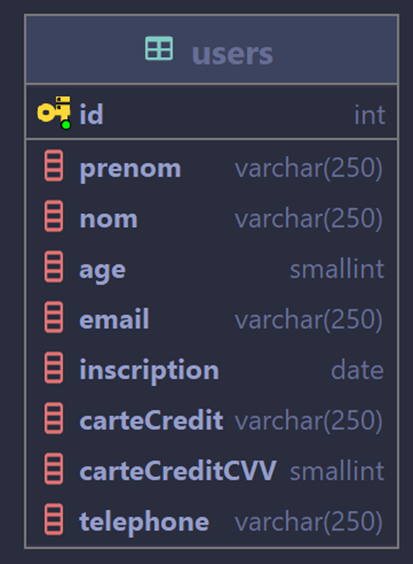
Pour vous éviter de devoir ouvrir le fichier de backup, voici la définition de la table users qui sera utilisée durant ce labo :
Les index
Une fois que vous êtes connectés et prêts à exécuter des requêtes, essayez la commande suivante et mesurez le temps de réponse :
SELECT * FROM users WHERE email = 'Anglina.Durand@hotmail.fr';
SELECT * FROM users WHERE id = 42;
Ne trouvez-vous pas cela étrange ? Une telle différence alors que le nombre de lignes retournées est le même et que les deux requêtes se ressemblent fortement. Pour comprendre ce qui se passe, nous allons voir l’un des outils d’analyse le plus important de SQL : l’analyseur de requêtes. Ce dernier permet d’obtenir un plan d’exécution et de comprendre le déroulement de la requête. Il existe plusieurs instructions en T-SQL qui permettent d’activer le plan d’exécution réelle (et non celui qui est planifié) :
- SET STATISTICS PROFILE ON
- SET STATISTICS XML ON
Le premier permet d’obtenir le plan au format texte qui est lisible pour un humain. Le second permet d’avoir le plan au format XML. C’est celui qu’on utilise le plus souvent, car il fournit plus d’informations. Par exemple, le site Supratimas permet d’avoir une représentation visuelle à partir du fichier XML.
Nous obtenons les résultats suivants pour les deux requêtes (respectivement query 1 et query 2) :
- Query 1:
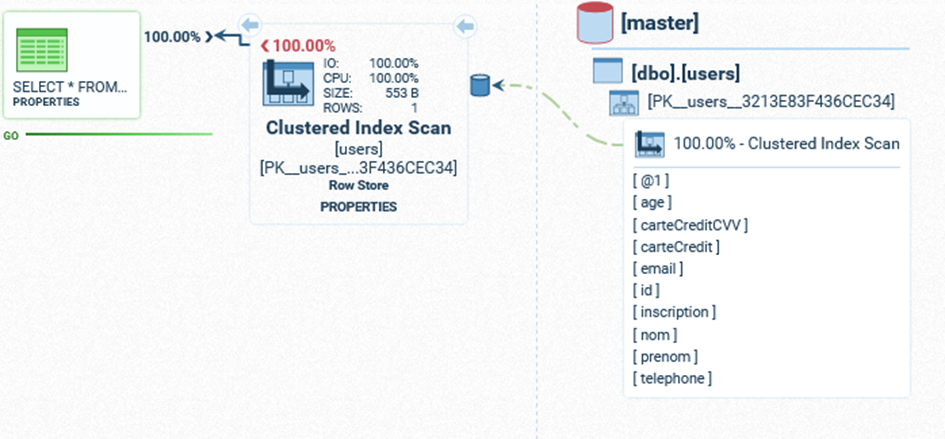
- Query 2:
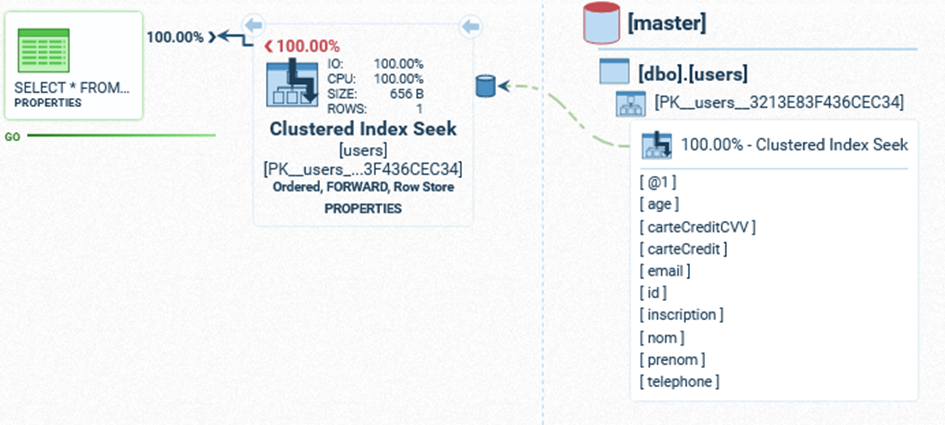
Maintenant, vous devriez savoir pourquoi la première requête est bien plus longue que la seconde.
La première a utilisé un scan séquentiel de la table (Index Scan) qui la force à la parcourir entièrement.
Tandis que la seconde requête a utilisé un Index Seek qui a permis d'accélérer le processus de recherche.
Il est intéressant de noter qu'on a utilisé un index alors qu’aucun index n'est spécifié dans la définition de la table.
Pouvez-vous expliquer pourquoi (voir : https://docs.microsoft.com/en-us/sql/relational-databases/tables/create-primary-keys?view=sql-server-ver15 ) ?
Nous sommes capables de comprendre pourquoi une requête est lente, nous allons essayer d’y remédier.
Pour cela, nous allons créer un index sur la colonne email.
Utilisez la commande suivante :
CREATE INDEX email_index ON users(email);
Maintenant, si on réexécute la requête de recherche (query 1), nous avons un bien meilleur temps. Voyons voir son plan d’exécution :
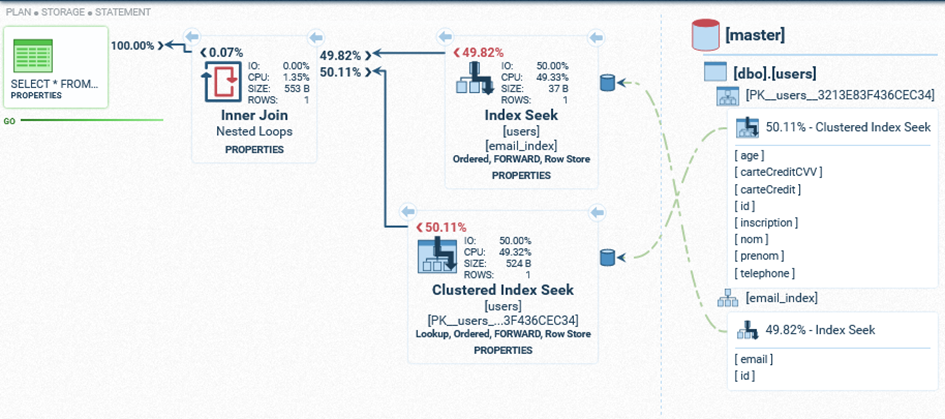
- Nouvelle requête:
SELECT TOP 100 COUNT(*) as nbr, email FROM users GROUP BY email ORDER BY nbr;

SQL Server va utiliser l’index pour la première partie de la query (SELECT TOP 100 COUNT(*) as nbr, email FROM users GROUP BY email ORDER BY nbr), mais il sera obligé de trier chacune de ces lignes pour le ORDER BY.
Il n’est pas possible de créer un index sur la colonne nbr, car elle n’existe pas dans la table mais uniquement durant la requête.
Les index ne sont donc pas une solution miracle qui améliore toutes les requêtes. Il faut les placer judicieusement pour éviter des pertes de performance lors des mises à jour de ces derniers. Il n’est pas non plus possible de construire un index multicolonnes où on stockerait le résultat du COUNT. La solution se trouve du côté des vues matérialisées. Cependant, ceci ne sera pas abordé durant le laboratoire.
Enfin, il est important de comprendre l’ordre de tri d’un index lorsque nous utilisons plusieurs colonnes. Si nous analysons la requête suivante :
SELECT TOP 1000 * FROM users ORDER BY nom, prenom, inscription;
Nous voyons qu’elle met un certain temps.
Si on crée un index via cette commande :
CREATE INDEX index_nom ON users (nom);
Nous verrons un résultat intéressant: l’index est complètement ignoré !
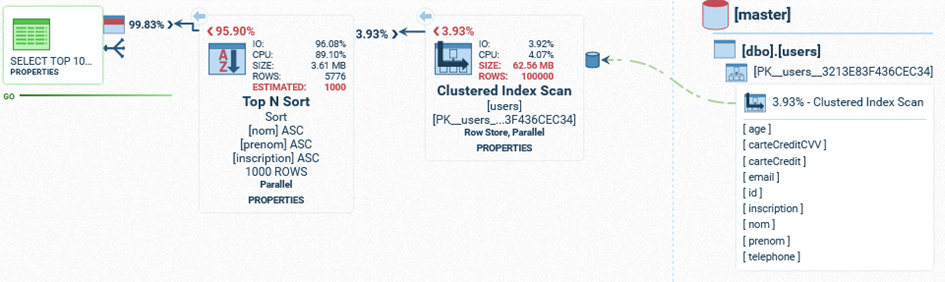
En effet, l’index simple ne contient qu’une seule colonne : nom.
SQL Server va estimer que l’index ne sera pas suffisant pour accélérer la requête.
En effet, même en se basant sur l’index, SQL Server devra continuer le tri pour les prénoms et dates d’inscription.
En forçant l’utilisation de l’index, nous obtenons une requête dont le temps d’exécution augmente.
La raison est la suivante : SQL Server se rend compte que le tri aura besoin de plus de colonnes que l’index.
Par exemple : l’index contient la clé Adam et l’ensemble des lignes qui possèdent un nom égal à cette valeur.
Mais il faudrait pouvoir trier cet ensemble de lignes avec les prénoms et les dates d’inscription.
Donc, le système devra faire une jointure des lignes des index avec la table users pour récupérer ces informations.
Ensuite, il pourra faire le tri en fonction des trois colonnes et renvoyer l’ensemble des lignes désirées.
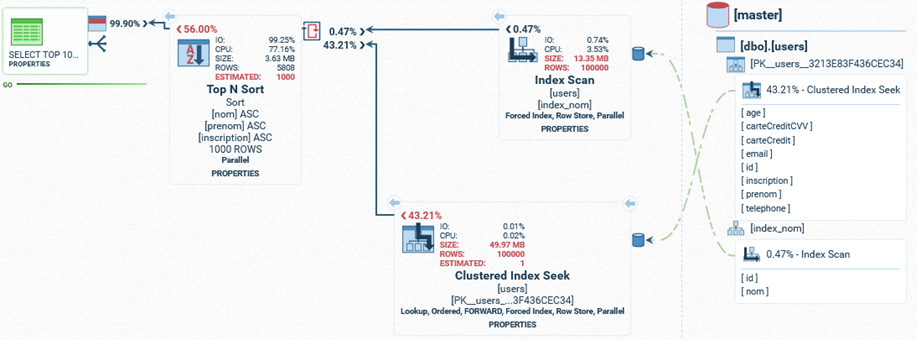
De manière générale, retenez que si la base de données préfère éviter l’utilisation d’un index, c’est qu’elle a estimé qu’il était préférable de s’en passer. Il est assez rare qu’une base de données se trompe sur l’estimation de ses plans d’exécutions (voir partie : Le Query Optimizer). Si vous désirez exécutez la commande de votre côté, voici la requête :
SELECT TOP 1000 * FROM users WITH (INDEX(index_nom)) ORDER BY nom, prenom, inscription ;
Enfin, si nous créons un index qui entièrement façonné pour cette requête, nous ferons un index multicolonnes qui reprend les 3 colonnes de la requête :
CREATE INDEX multi_index ON users (nom, prenom, inscription);
Nous obtiendrons donc le résultat suivant en analysant la requête (environ 600 ms d’exécution):
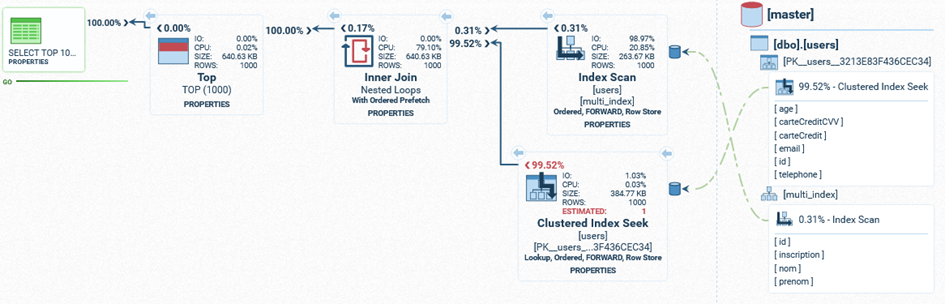
Vous pouvez voir qu’il n’y a aucune opération de tri.
Etant donné que l’index multicolonnes contient les colonnes nécessaires pour le tri (et donc le bon ordre), il suffit de le parcourir pour trouver l’ensemble des id des lignes dans la table et d’effectuer une jointure pour récupérer le reste des colonnes.
Trouver le bon index n’est donc pas facile et demandera une bonne analyse de la requête, mais aussi des données présentes dans la base de données.
À l’examen, vous n’aurez pas un cas aussi délicat.
Vous serez confrontés à des cas plus simples où vous ne devrez pas vous méfier des données présentes dans la base de données.
Soyez donc rassurés !
Exercices sur les index
Trouvez les "meilleurs" index aux requêtes suivantes tout en respectant les contraintes données :
SELECT COUNT(*) FROM users WHERE inscription BETWEEN '2022-01-01' AND '2023-01-01';
-- Minimum d'espace
SELECT COUNT(*) FROM users WHERE age >= 65;
-- Accès à l'index uniquement
SELECT nom, prenom FROM users WHERE inscription BETWEEN '2023-01-01' AND '2023-02-01';
Le Query Optimizer
Le Query Optimizer (QO) est un composant très courant des bases de données SQL qui vise à optimiser les requêtes.
En effet, un QO crée une Query Execution Plan (QEP) (c’est le résultat des analyses de requêtes que nous avons faites plus haut) qui indique :
- La séquence d’accès aux tables concernées par une requête
- La méthode d’accès aux données d’une table.
Imaginez une requête impliquant 5 tables. Les possibilités d’ordre d’interrogation des tables sont nombreuses. Les méthodes d’accès aux données d’une table sont également multiples :
- Table Scan (parcourir toute la table)
- Index Scan (parcourir l’index s’il en existe un dont une colonne clé est impliquée dans une clause WHERE/ORDER BY)
Dans certains cas, même si un index existe, un table scan peut être plus rapide (typiquement lorsque les table sont petites). De plus, la présence d’index peut ralentir l’exécution de commandes en écriture (INSERT/UPDATE/DELETE).
Pour une même requête devant être exécutée, il peut y avoir plusieurs plans d’exécution possibles. Lorsque le SGBD doit traiter une requête, il évalue les différents plans d’exécutions qu’il est en mesure d’envisager et il en élit un. C’est celui-là qui décrira la séquence d’actions à opérer pour arriver au résultat qui sera retourné à l’utilisateur.
Le QO prend en entrée :
- La requête et sa structure (les attributs, les tables, les clauses)
- Le schéma de la BD (description des tables et attributs, statistiques sur les tables et leur contenu)
Il fournit en sortie un plan d’exécution, déterminé sur base de plusieurs éléments.
Afin de procéder à cette élection, il analyse les coûts en termes de ressource ainsi que la rapidité d’exécution de chaque plan1 d’exécution et en fait la balance.
Afin de procéder à cette analyse, le QO a besoin de statistiques sur les tables et leur contenu.
Exemple : un index pourrait ne pas être utilisé si la densité des colonnes impliquées est trop élevée.
La densité exprime la distribution de l’unicité dans les données en question.
Exemple : la base de données de l’Henallux possède probablement une table étudiants.
Le champ Sexe a une densité plus élevée que le champ Prénom.
Ce dernier possède à son tour une densité plus élevée que le champ RegistreNational.
Un QEP impliquant l’exploitation d’un index possédant une densité élevée sera sans doute écarté au profit d’un QEP utilisant un index à densité faible.
Les partitions
Les partitions sont un moyen de séparer "physiquement" les données, mais cela reste invisible du côté "logique". Cette distinction permet d’interroger la base de données comme d’habitude (en utilisant le nom de la table) et ce sera le système qui déterminera quelle(s) partition(s) utilisée(s) pour la requête. * Un autre exemple (plus simple) pour bien comprendre la distinction entre "logique" et "physique" : votre système de fichier. D’un point de vue logique, vous avez des "disques" où vous mettez vos dossiers et fichiers. Ce n’est pas important si votre support physique est un disque dur ou un SSD : vous gérez vos fichiers de la même façon. Mais votre système d’exploitation, celui qui va gérer le côté physique, n’agira pas de la même manière en fonction du support physique.
Nous allons créer une partition qui distribuera les gens en fonction de leur date d’inscription. Pour cela, il faudra :
- Des groupes de fichiers pour stocker les données des futures tables filles
- Ajouter un fichier par groupe (pour le stockage des données). Il est possible de paramétrer ce fichier, mais nous irons au plus simple pour ce laboratoire (la liste des options est disponible ici : https://docs.microsoft.com/fr-fr/sql/t-sql/statements/alter-database-transact-sql-file-and-filegroup-options?view=sql-server-ver15#arguments)
- La fonction de partition : elle permettra de "trier" les données selon un critère
- Le schéma de partition : il permet de faire le lien entre la fonction de partition et les groupes de fichiers
- La table mère : elle sera utilisée pour la partie "logique" et sera physiquement représentée via la partition.
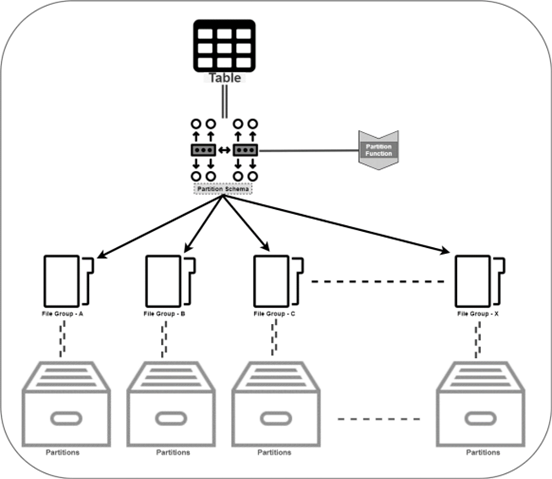
- Les groupes de fichiers Pour créer ce groupe de fichiers (qui contiendra l’ensemble des fichiers nécessaires à chaque partition), utilisez les instructions suivantes :
ALTER DATABASE exercices
ADD FILEGROUP UsersFg1;
ALTER DATABASE exercices
ADD FILEGROUP UsersFg2;
ALTER DATABASE exercices
ADD FILEGROUP UsersFg3;
ALTER DATABASE exercices
ADD FILEGROUP UsersFg4;
- Ajouter un fichier par groupe de fichiers. Il vous suffit d’utiliser les instructions suivantes :
ALTER DATABASE exercices
ADD FILE
(
NAME = UsersFg1dat,
FILENAME = '/var/opt/mssql/data/UsersFg1dat.ndf'
)
TO FILEGROUP UsersFg1;
ALTER DATABASE exercices
ADD FILE
(
NAME = UsersFg2dat,
FILENAME = '/var/opt/mssql/data/UsersFg2dat.ndf'
)
TO FILEGROUP UsersFg2;
ALTER DATABASE exercices
ADD FILE
(
NAME = UsersFg3dat,
FILENAME = '/var/opt/mssql/data/MoviesFg3dat.ndf'
)
TO FILEGROUP UsersFg3;
ALTER DATABASE exercices
ADD FILE
(
NAME = UsersFg4dat,
FILENAME = '/var/opt/mssql/data/UsersFg4dat.ndf'
)
TO FILEGROUP UsersFg4;
- La fonction de partition. Nous voulons le fonctionnement suivant :
| Numéro de partition | Date d’inscription |
|---|---|
| 1 | <= 21/03/2021 |
| 2 | > 21/03/2021 ET <= 21/09/2021 |
| 3 | > 21/09/2021 ET <= 21/03/2021 |
| 4 | > 21/03/2021 |
L’instruction pour créer une fonction de partition correspondant au fonctionnement décrit plus haut est (attention, les dates sont au format aaaa/mm/jj) :
CREATE PARTITION FUNCTION UsersPartitionFunction (date) AS RANGE LEFT FOR VALUES ('2021-03-21', '2021-09-21', '2022-03-21');
Il est important de noter qu’il n’est pas possible de créer des partitions sur tous les types de données. Par exemple, les chaînes de caractères ne sont pas supportées.
Type de données de la colonne utilisée pour le partitionnement. Tous les types de données sont utilisables comme colonnes de partitionnement, à l’exception de text, ntext, image, xml, timestamp, varchar(max), nvarchar(max), varbinary(max), des types de données d’alias ou des types de données CLR définis par l’utilisateur. 2
L’instruction RANGE LEFT permet d’indiquer que la limite de la borne supérieure est incluse.
Le RANGE RIGHT inclut la valeur de la borne inférieure.
Si nous avions utilisé ce dernier, le tableau plus haut aurait été le suivant :
| Numéro de partition | Date d’inscription |
|---|---|
| 1 | < 21/03/2021 |
| 2 | >= 21/03/2021 ET < 21/09/2021 |
| 3 | >= 21/09/2021 ET < 21/03/2021 |
| 4 | >= 21/03/2021 |
- Schéma de partitionnement. Ce schéma permet de faire le lien entre la règle de partitionnement et les partitions physiques. Pour le créer, voici l’instruction :
CREATE PARTITION SCHEME UsersPartitionScheme AS PARTITION UsersPartitionFunction TO (UsersFg1, UsersFg2, UsersFg3, UsersFg4);
- Création de la table mère. La table mère correspond à la partie logique de la partition. C'est elle qui sera interrogée dans nos SELECT, INSERT, etc. Mais le système déterminera quelle(s) partition(s) utiliser en fonction de notre requête. Voici l’instruction :
CREATE TABLE users_p (
id int identity,
prenom varchar(250),
nom varchar(250),
age smallint,
email varchar(250),
inscription date,
carteCredit varchar(250),
carteCreditCVV smallint,
telephone varchar(250),
PRIMARY KEY (id, inscription)
)
ON UsersPartitionScheme (inscription);
Vous noterez qu’il faut inclure la colonne utilisée pour le partitionnement dans la clé primaire.
Il vous suffit maintenant de remplir cette table en vous basant sur la table users.
Voici l’instruction (attention, cette table est très grande et le copiage des données prend un certain temps):
INSERT INTO users_p(prenom, nom, age, email, inscription, carteCredit, carteCreditCVV, telephone) SELECT prenom, nom, age, email, inscription, carteCredit, carteCreditCVV, telephone FROM users;
Si on exécute la requête suivante :
SELECT TOP 500 * FROM users_p WHERE inscription = '2021-03-21'
On verra qu’une seule partition est lue : la partition n°1 (en suivant la fonction de répartition, il est facile de déterminer que les lignes recherches ne peuvent se trouver qu'à cet endroit).
Exercices partition
Vous êtes en charge d’une boutique en ligne connue mondialement. On souhaite obtenir des statistiques de vente par continent. L’historique des commandes comporte le pays où la commande a été faite. Comment vous vous y prenez pour améliorer la recherche des commandes ? Est-ce que cela semble une bonne idée ? Donnez vos hypothèses pour expliquer votre réponse.
Imaginons que cette boutique souhaite faire un système de recommandations. Elle a collecté assez de données pour savoir si 2 profils sont liés et le type de la relation ("frère/sœur", "amis", …). Il sera ainsi possible de récupérer certains profils pour des fêtes bien précises. On vous propose une partition sur la table des utilisateurs. Quel critère vous prendriez ? Justifiez votre choix. On vous propose de partitionner en fonction de l’âge. Ceci ne semble pas être une bonne idée, justifiez pourquoi.
Notes de bas de page
-
Pour certaines requêtes complexes impliquant un nombre élevé de plans d’exécutions, il est possible que le QO n’évalue pas l’ensemble des plans. ↩
-
Source : https://docs.microsoft.com/fr-fr/sql/t-sql/statements/create-partition-function-transact-sql?view=sql-server-ver15 ↩